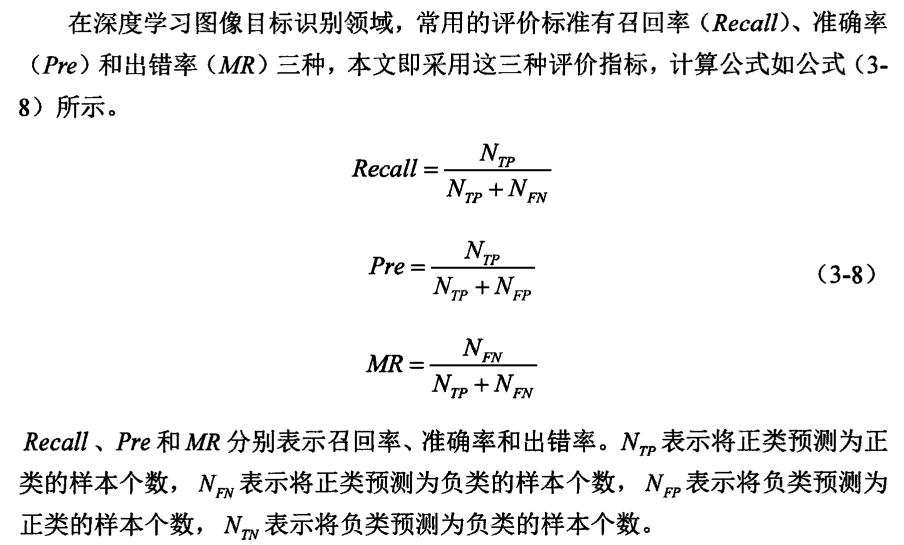
多线程进阶
线程与进程java默认2个线程,main,gc真实的线程时底层C++调用的,并不是javacup核心数,就是并行的线程数单核CUP,要多线程并行,就是用并发实现宏观并行线程状态Newrunningblockedwaitingtime_waitingterminalwait与sleep来自不同的类都会释放cup,但wait释放锁,即释放资源,sleep不释放wait只在同步代码块,sleep任意线程是一个资源类,没有任何附属操作,OOP编程资源类包含属性,方法资源类方法同步启动线程操作资源类...